if X is continuous, then FX(x) is continuous and differentiable almost everywhere. The probability density function (pdf) is defined as:
fX(x)=dxdFX(x)
if X is discrete, then FX(x) is a step function and the probability mass function (pmf) is defined as:
pX(xi)=P(X=xi)
Central Limit Theorem: the distribution of the sum (or average) of a large number of independent, identically distributed variables will be approximately normal, regardless of the underlying distribution.
It outputs a real number that represents the length or size of a vector in a vector space.
x=(x1,x2,…,xn)↦f(x)=∥x∥
Non-negativity: ∀x∈Rn,∥x∥≥0
Definiteness: f(x)=0⟺x=0
Homogeneity: ∀x∈Rn,∀t∈R,f(tx)=∣t∣f(x)
Triangle inequality: ∀x,y∈Rn,f(x+y)≤f(x)+f(y)
∥x+y∥≤∥x∥+∥y∥
A norm is non-negative, only the zero vector has a norm of zero, scaling a vector by two doubles its norm, and the direct distance cannot be greater than the detoured distance.
∥x∥p=(∑i=1n∣xi∣p)p1,p≥1
L1 norm: ∥x∥1=∑i=1n∣xi∣
Manhattan distance.
L2 norm: ∥x∥2=∑i=1n∣xi∣2
Euclidean distance.
L-infinity norm: ∥x∥∞=maxi∣xi∣
∥(3,4)∥∞=max{3,4}=4
∥A∥F=∑i=1m∑j=1n∣aij∣2=tr(ATA)
Frobenius norm: A=[1324]
∥A∥F=12+22+32+42=30
It is the square root of the sum of the absolute squares of its elements.
A set of vertors X={x1,x2,...,xn} in a vector space V is said to spanV if every vector in V can be expressed as a linear combination of the vectors in X.
Span is the entire region that can be reached by scaling and adding the given vectors.
A set of vectors {v1,v2,...,vn} is said to be linearly independent if the only solution to the equation α1v1+α2v2+...+αnvn=0 is α1=α2=...=αn=0.
Column rank: The maximum number of linearly independent column vectors in a matrix.
Row rank: The maximum number of linearly independent row vectors in a matrix.
If one row vector is a combination of other row vectors, then it is linearly dependent.
The number of rows that are removed due to redundancy is the Rank of the matrix.
Due to the redundancy, the number of directions which is vanishing is the Nullity of the matrix.
The quadratic form xTAx gives a scalar value that measures the cost, energy, or weighted magnitude of the vextor x, according to the quadratic surface defined by the matrix A.
Positive definite: Q(x)>0,∀x=0
Positive semi-definite: Q(x)≥0,∀x=0
Negative definite: Q(x)<0,∀x=0
Negative semi-definite: Q(x)≤0,∀x=0
Indefinite: Q(x) can be positive or negative for different x=0
행렬의 정부호성(양의 정부호, 양의 준정부호, 음의 정부호, 음의 준정부호, 부정정부호)
ATA=ATA⟹Q(x)=xTATAx=(Ax)T(Ax)=∥Ax∥2≥0
Always positive semi-definite because it is the square of the norm of the vector Ax.
A matrix A that appears complicated in the original coordinate system becomes the diagonal matrix Λ when expressed in the eigenvector coordinate system.
A=SΛS−1
In the eigenvector basis, the matrix A becomes the diagonal matrix Λ.
최근 급격히 발전 중인 거대 언어 모델(LLM)의 강화학습 정렬 기술인 RLHF(Reinforcement Learning from Human Feedback)에서 다수의 인간 피드백 에이전트가 제시하는 보상 함수(Reward Function)의 기댓값 추정 신뢰도 보장을 위해 대수의 법칙이 기반으로 자동 작동함.
디퓨전 이미지 생성 모델(Diffusion Model)의 순방향 확산 과정에서 연속적으로 임의의 미세 노이즈를 누적 주입할 때, 각 단계의 독립 노이즈 분포와 무관하게 최종 잠재 벡터의 분포가 완전한 정규분포(가우시안 노이즈)로 정렬되는 물리적 기초가 바로 중심극한정리에 기인하는바, 차세대 생성 AI 아키텍처 설계를 위한 수학적 필수 뼈대로 활발히 응용되고 있음.
다중 에이전트 시스템(MAS, Multi-Agent System)이란 하나의 환경에서 자율성·반응성·능동성·사회성을 갖춘 다수의 에이전트가 통신·협상·조정을 통해, 단일 에이전트로 해결하기 어려운 복잡한 대규모 문제를 분산 협업으로 해결하는 지능형 시스템 아키텍처이다.
단일 거대 LLM의 할루시네이션, 제한된 컨텍스트 윈도우, 다단계(Multi-step) 태스크의 성능 저하를 극복하기 위해 역할을 특화(Divide & Conquer)하고, A2A(Agent-to-Agent) 협업과 MCP(Model Context Protocol) 도구 연동으로 신뢰성과 비용 효율을 동시에 확보하려는 필요성에서 대두되었다.
상호 검증 기반 신뢰도 향상: 서로 다른 관점의 에이전트가 결과를 토론(Debate)·자아 성찰(Self-Reflection)하여 할루시네이션을 억제하고 의사결정 정확도를 높인다.
A2A와 MCP의 상호 보완 통합: 고수준의 에이전트 간 협업은 A2A로, 개별 에이전트의 도구·데이터 접근은 MCP로 처리하는 이중 규격 하이브리드 아키텍처로 수렴한다. 두 표준은 각각 별도 거버넌스로 오픈 표준화가 진행되어, A2A는 2025년 6월 Google이 Linux Foundation에 기증해 Agent2Agent 프로토콜 프로젝트로 운영되고, MCP는 2025년 12월 Anthropic이 Linux Foundation 산하 directed fund인 Agentic AI Foundation(AAIF)에 기증하였다.
프레임워크 선택 전략: 복잡·대규모 상태 오케스트레이션은 LangGraph, 역할 기반 협업은 CrewAI, 대화형 합의는 AutoGen을 활용하되, 조직 요구에 따라 혼합 적용한다.
T. J. McCabe, "A Complexity Measure," IEEE Transactions on Software Engineering, vol. SE-2, no. 4, pp. 308-320, 1976. https://doi.org/10.1109/TSE.1976.233837
CONV extracts features, POOL downsamples feature maps, and FC makes the final prediction.
Why CNNs use over ANNs for image processing
Computationally efficient
Using Filters to capture spatial features
Sharing weights across the image
Overfitting
The model essentially memorizes the training data, leading to poor performance on unseen data
To prevent overfitting, we can use techniques like:
Dropout: Randomly dropping out neurons during training to prevent co-adaptation
Batch Normalization: Normalizing the inputs of each layer to stabilize learning
L1/L2 Regularization: Adding a penalty to the loss function to discourage large weights
L1 regularization adds a penalty based on the absolute value of the weights (can be zero, can make model sparse and useful for feature selection.)
L2 regularization adds a penalty based on the squared value of the weights (not can be zero, reduce model complexity and overfitting.)
Data Augmentation: Creating new training samples by applying transformations to existing data
ReLU
If the input is below zero, ReLU does output 0.
If the input is above zero, it outputs the input value itself.
max(0, x)
ReLU can output any number from 0 to infinity, which allows it to capture a wide range of features in the data.
It fixes gradient vanishing problem by allowing gradients to flow through the network without being squashed to zero, which can happen with activation functions like sigmoid or tanh.
Sigmoid: Binary Classification
Softmax: Multi-class Classification
Backpropagation: sends the error backward through the network and calculates gradients, so the model knows how to update its weights and biases.
Gradient Descent
It uses Backpropagation to calculate the exact slope (the gradient) of the error (loss).
Then it takes a step in the opposite direction of the gradient to minimize the error.
It repeats this interative process until it reaches a local minimum.
Vanishing Gradient Problem
The gradient becomes too small, so earlier layers learn very slowly or almost stop learning.
ReLU helps mitigate this problem by allowing gradients to flow through the network without being squashed to zero.
Learning Rateα
It's a hyperparameter that controls how big of a step the model takes down the slope.
If α is too small, the model will take tiny steps and may take a long time to converge.
If α is too large, the model may overshoot the minimum and diverge.
Precision: TP+FPTP
Of all the patients the model predicted as having the disease, how many actually have the disease?
Recall: TP+FNTP
Of all the patients who actually have the disease, how many did the model successfully catch?
Recall is more important in medical diagnosis because we want to minimize false negatives (missing a disease).
Sliding Window
Computationally expensive because it requires multiple passes over the image with different window sizes and strides.
Multiple scales are needed to detect objects of varying sizes, which further increases the computational cost.
Stride: controls the step size of the sliding filter. Larger stride means smaller output.
Edge
The points or pixels in an image where brightness or intensities change sharply.
Sobel filter
Prewitt filter
Canny edge detector
Padding: adds zeros around the image so the CONV does not shrink the feature map too much.
Keep the output dimension the same as the input dimension, we can use padding.
P=2F−1
Image Classification: Assigning a label to an entire image (e.g., cat, dog, car).
Object Detection: Identifying and localizing multiple objects within an image (e.g., bounding boxes)
Instance Segmentation: Identifying and segmenting each object instance in an image (e.g., pixel-level masks)
Momentum: uses an exponentially weighted average of past gradients to smooth updates and accelerate convergence.
RMSProp: uses an exponentially weighted average of squared gradients to adapt the learning rate for each parameter.
Adam: combines Momentum and RMSProp by using both the first moment, average gradient, and the second moment, average squared gradient.
Hyperparameters: learning rate, batch size, number of epochs, optimizer type, dropout rate, etc.
Supervised Learning: The model learns from labeled data, classification, regression.
Unsupervised Learning: The model learns from unlabeled data, clustering.
Loss/Cost function: an estimate of how far the model's predictions are from the actual target/answer.
AI is a broad concept of machines performing human-like tasks.
ML is a subset of AI that learns from data
DL is a subset of ML that uses deep neural networks with many layers.
ML's major problem
insufficient data
non-representative training data
poor-quality data
irrelevant features
overfitting
underfitting
When we use ML?
a large amount of data for finding patterns and making predictions
too many rules or too much complexity for humans to handle
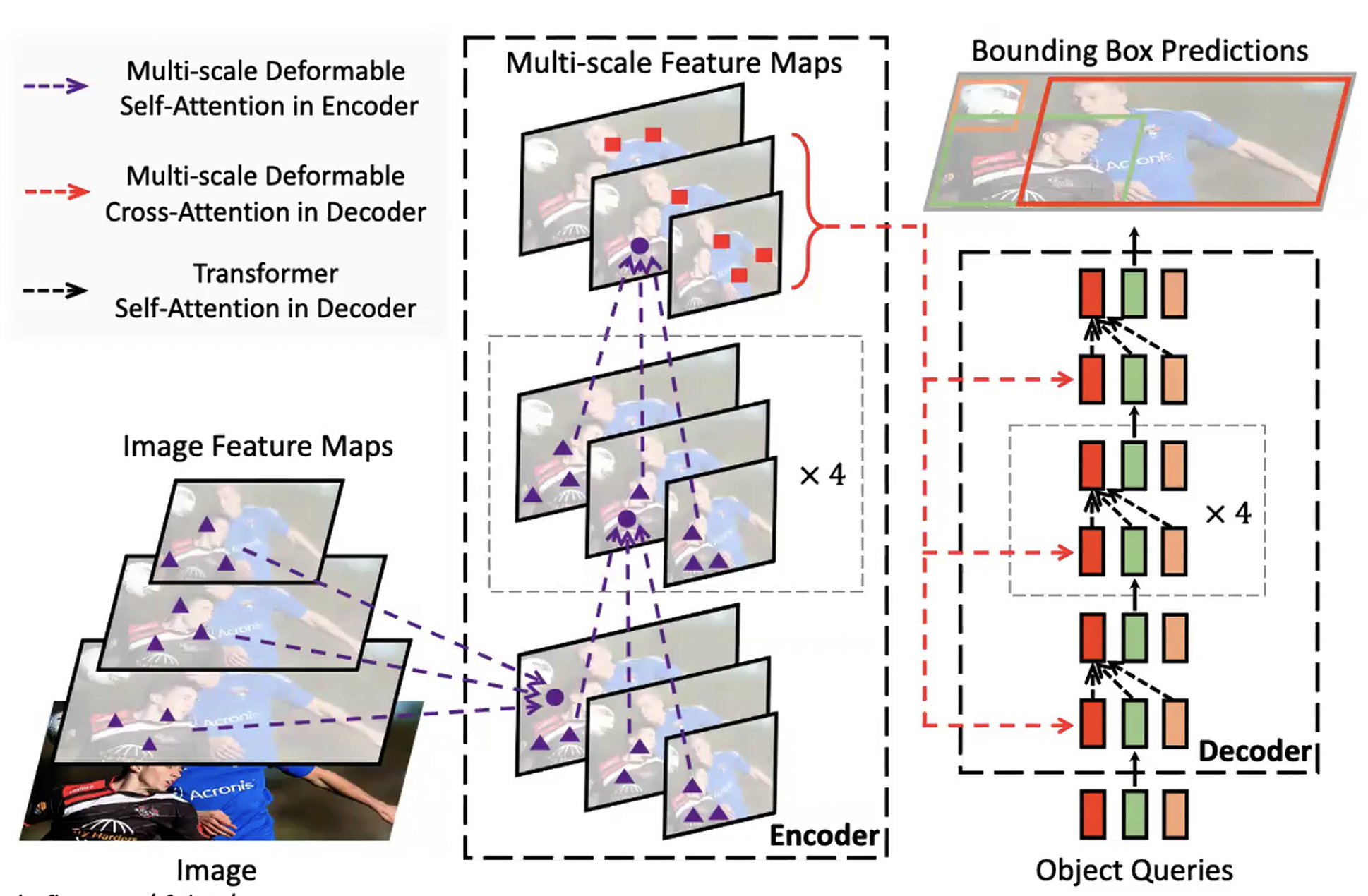
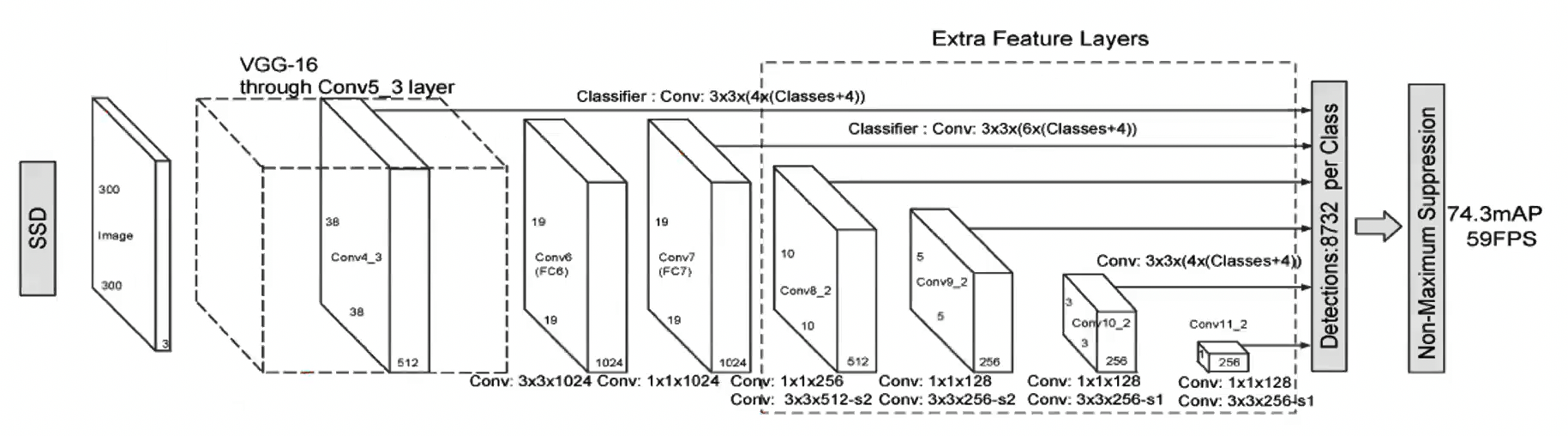
Faster R-CNN: Propose regions first, then classify them
RPN: Region Proposal Network, which generates candidate object proposals
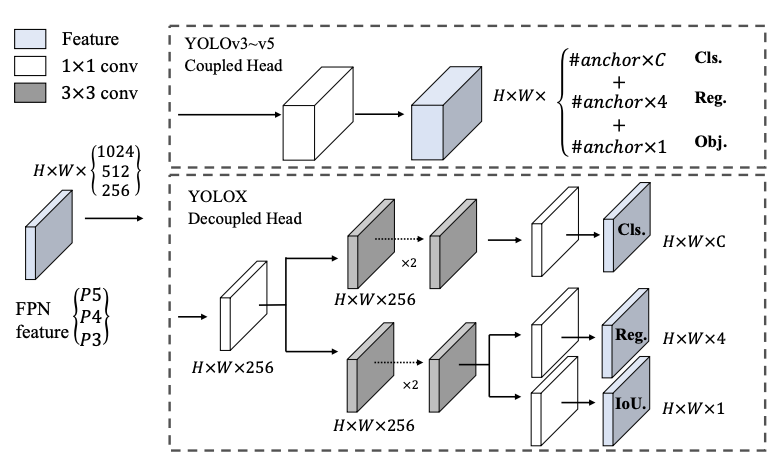
YOLO: Predict boxes and class probabilities directly from the image in one pass
Anchor boxes: predefined bounding boxes of different sizes and aspect ratios used to predict the location of objects in YOLO.
NMS: Non-Maximum Suppression, selects the best bounding box among overlapping boxes based on confidence scores.
1×1 convolution mixes channel information and can reduce the number of channels, so later convolutions become cheaper.
Inception module: learns small, medium, and large visual features at the same time.
Transfer Learning Strategies:
First, if the new dataset is small and similar to the original dataset, we can use the pre-trained model directly.
Second, if the dataset is similar but has different classes, we freeze the convolutional layers and train only the fully connected classification layer.
Third, if the dataset is small but not very similar, we freeze the early convolutional layers and fine-tune the later convolutional layers plus the FC layer.
Finally, if the dataset is large and different, we can fine-tune the whole network.
IoU: Intersection over Union, a metric used to evaluate the accuracy of object detection models by comparing the predicted bounding box with the ground truth bounding box.
Computational Complexity: Traning and inference can be computationally intensive, requiring substantial resources (high resolution images or large datasets).
Small-Object Segmentation: may struggle with accurately segment very small objects due to limited pixel information.
Data Requirements: Training requires a large amount of annotated data, which can be time-consuming and expensive to acquire.
Limited Generalization to Unseen Categories: The model's ability to generalize to unseen object categories is limited.
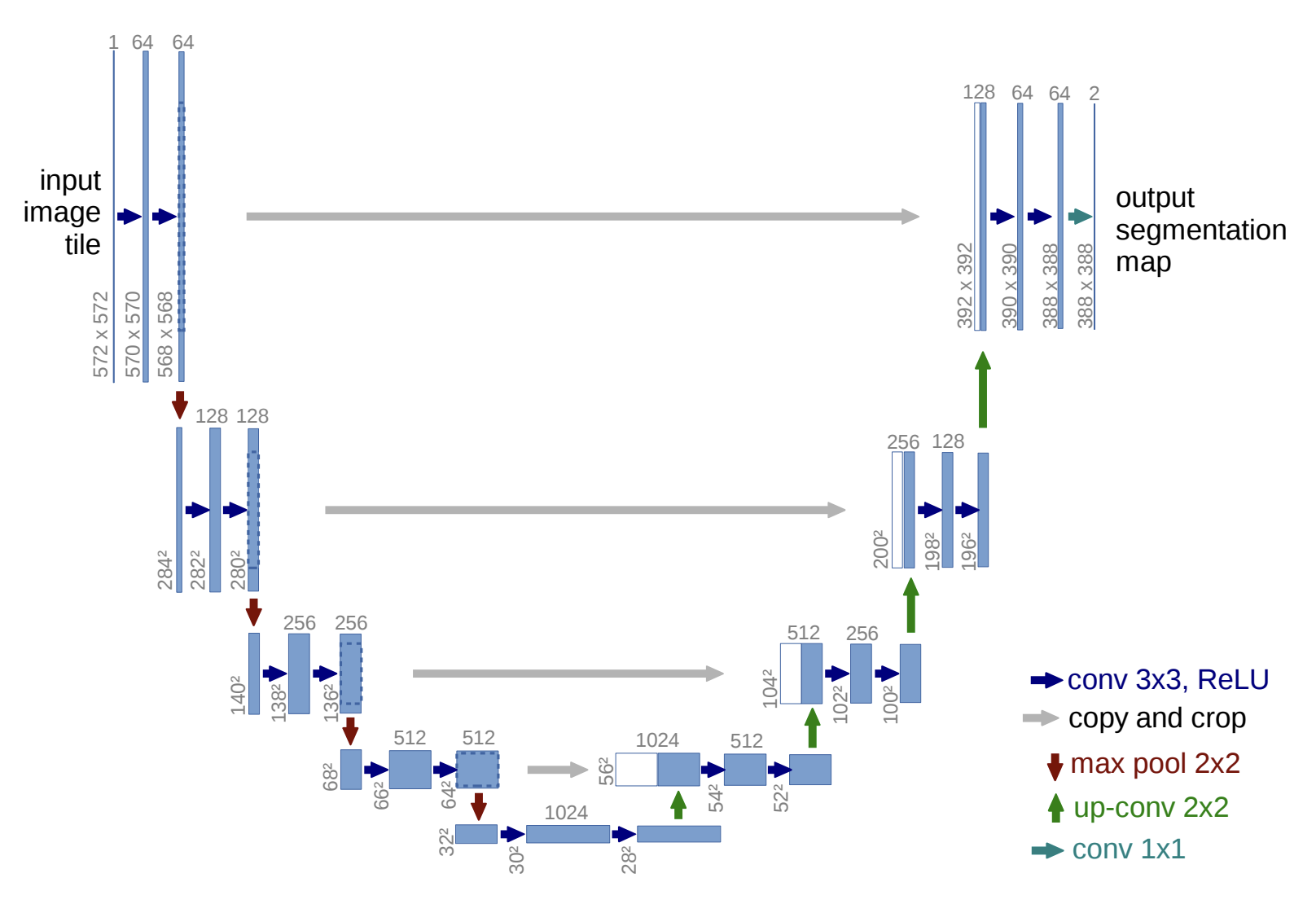
Ronneberger, O., Fischer, P., & Brox, T. (2015). U-Net: Convolutional networks for biomedical image segmentation. In N. Navab, J. Hornegger, W. M. Wells, & A. F. Frangi (Eds.), Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015 (Vol. 9351, pp. 234–241). Springer. https://doi.org/10.1007/978-3-319-24574-4_28
Check the probabilities of each detection and keep ones with score above a certain threshold (0.7)
For remaining boxes,
a. Box with highest score is the detection results.
b. Discard any remaining boxes with IoU > 0.5 with final detected box
c. i.e. overlap with the box with highest score.